










Experiments
An experiment is Gremlin’s term for injecting fault into some part of a system in a safe and secure way. This can include causing network outages, creating latency, shutting down hosts, and exhausting compute resources. In addition to running ad-hoc experiments, you can also schedule regular or recurring experiments, create experiment templates, and view reports of historical experiments. Experiments form the foundation of Gremlin’s other features, such as Scenarios and Test Suites.
Experiment categories
Gremlin provides three categories of experiments:
- Resource experiments: test against sudden changes in consumption of computing resources.
- Network experiments: test against unreliable network conditions.
- State experiments: test against unexpected changes in your environment, such as power outages, node failures, clock drift, or application crashes.
The tables below show the experiments that belong to each category.
Resource Experiments
Resource experiments consume compute resources like CPU, memory, and I/O throughput.
State Experiments
State experiments modify the state of a target so you can test for auto-correction and similar fault-tolerant mechanisms.
Network Experiments
Network experiments test the impact of lost or delayed traffic to a target. Test how your service behaves when you are unable to reach one of your dependencies, internal or external. Limit the impact to only the traffic you want to test by specifying ports, hostnames, and IP addresses.
How to run an experiment
There are three ways to run an experiment: using the Gremlin web app, REST API, and Gremlin CLI (command-line interface). To run an experiment using the Gremlin web app:
- Log into the Gremlin web app and click on the Experiments link in the left-hand navigation menu.
- Click the New Experiment button.
- Select the type of system that you want to run the experiment on. Gremlin supports host, container, and Kubernetes-based targets (for running experiments on applications and serverless functions, see Failure Flags).
- After selecting a type, you’ll need to refine your selection to specific targets. For all three target types, you can select specific targets individually, or by using tags (or “Selectors” for Kubernetes). The default view groups targets by tag, but you can click the Exact button to switch to the individual target list.
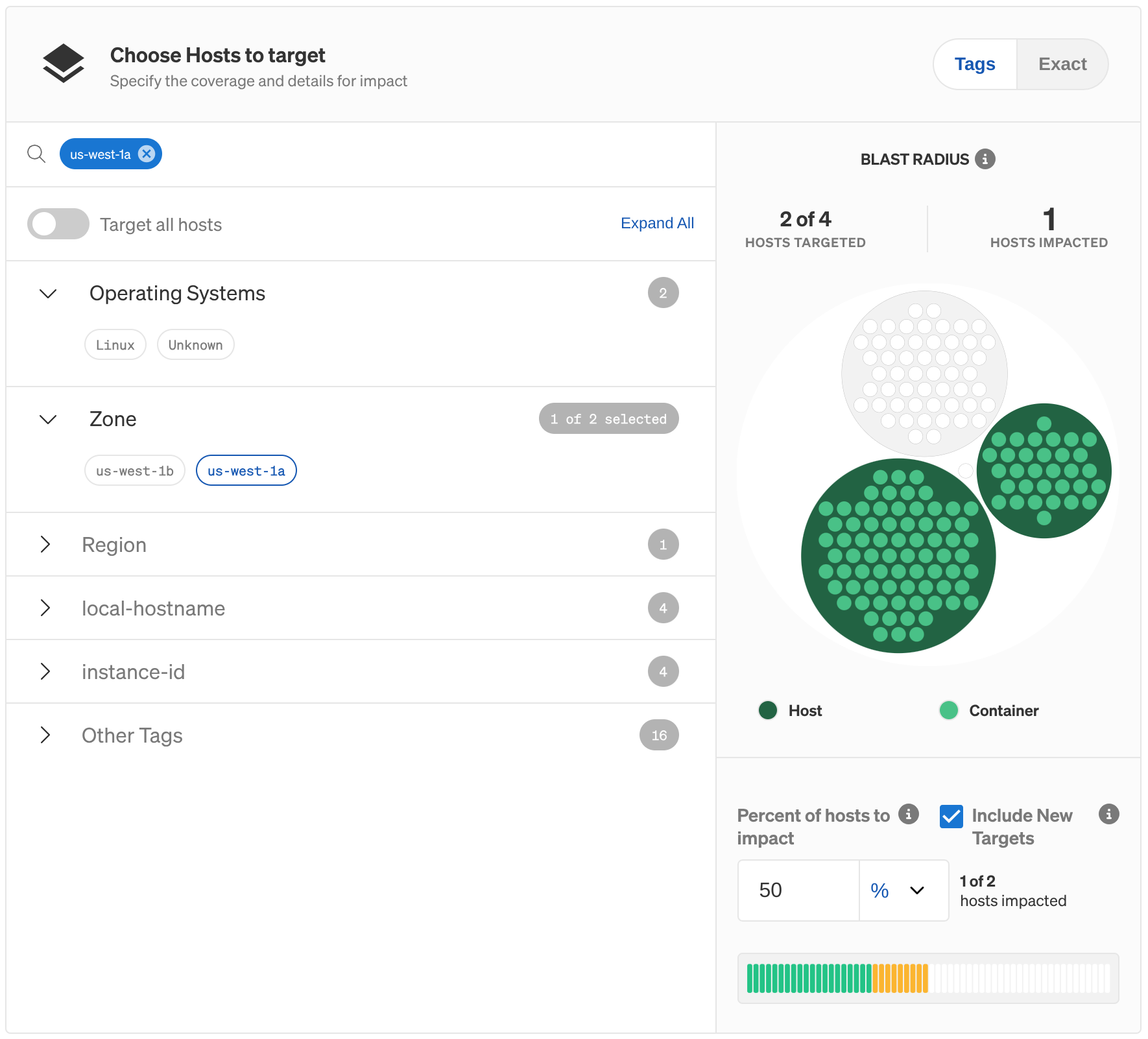
- You can review and refine your selection further using the Blast Radius graph. The graph shows each host, container, and Kubernetes resource, and will highlight the resources that your experiment will impact. You can hover the mouse over any item in the graph to see its name.
- If you want to limit the impact to a random subset of resources, you can use the Percent to impact box. For example, if you have two hosts and set this value to 50%, Gremlin will randomly choose one of the hosts as the experiment target when the experiment is run. If you'd rather define a percentage instead of a number, use the drop-down box to switch units. See the image below for an example.
- By default, Gremlin will automatically include any newly-detected targets that match the target criteria. This is useful if, for example, your target is an autoscaling cluster and you want to include new nodes while the experiment is running. To prevent this behavior, uncheck the Include New Targets check box.
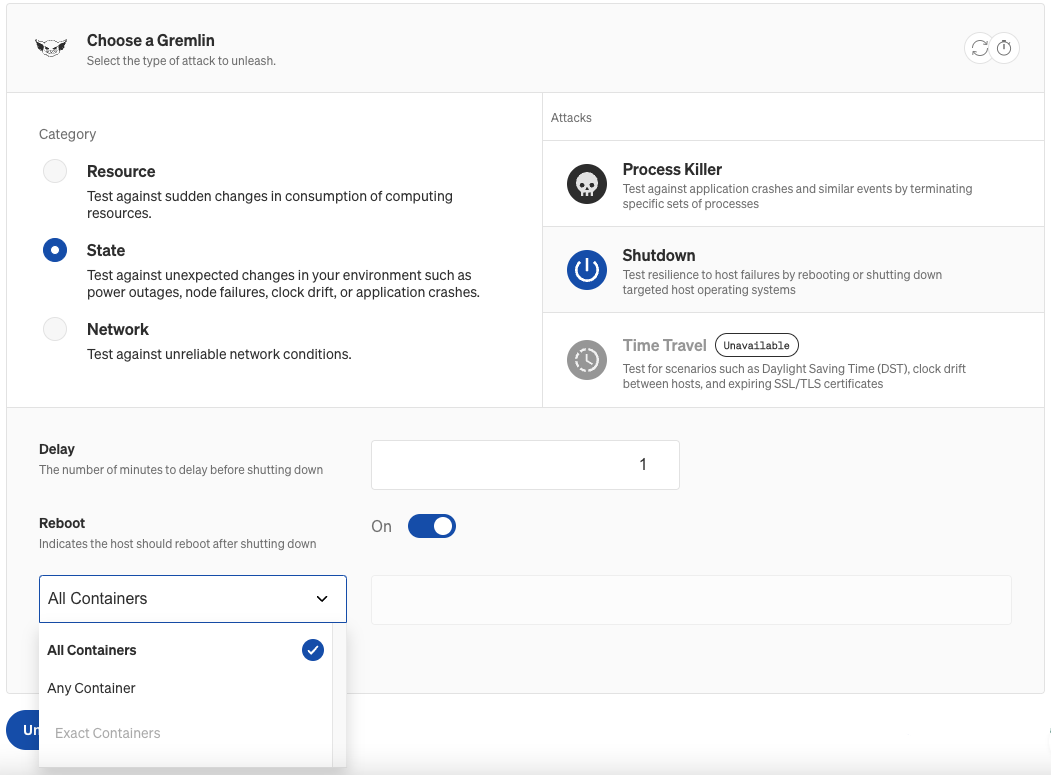
- Under Choose a Gremlin, configure the experiment that you want to run.
- Select the Category of the experiment, then click on the experiment name.
- Depending on the experiment you choose, you'll see different settings for setting up the experiment. Check each experiment’s documentation page to learn what each parameter does, and what values it allows.
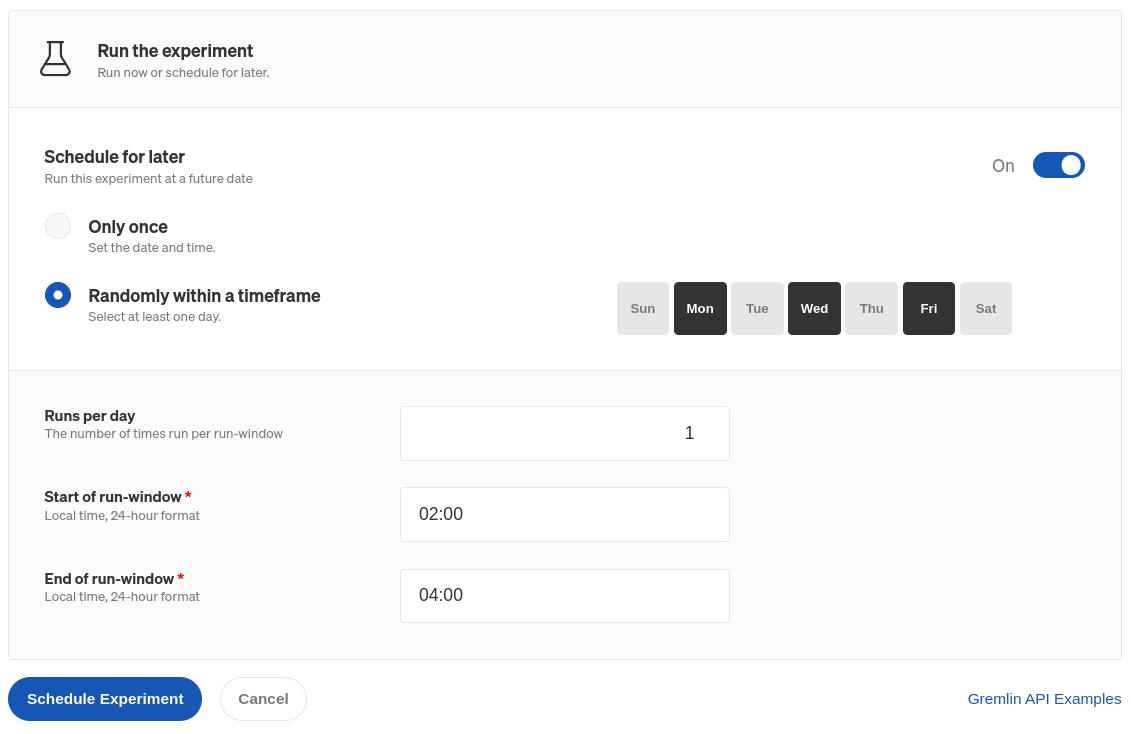
- If you want to schedule this experiment to run in the future, check the Schedule for later toggle.
- To run the experiment at one specific time, select Only once and enter a date and time.
- To run the experiment at random during a window, select Randomly within a time frame. You can choose one or more days of the week to run the experiment, how many times to run it each day, and the time window. Gremlin will select a random time during the window to run the experiment.
- Click Run Experiment to start the experiment (or Schedule Experiment to schedule it for later). After clicking Run Experiment, Gremlin brings up the experiment progress screen where you can track the progress of the experiment in real-time.
Monitoring system metrics using experiment visualizations
For certain resource experiments, Gremlin can automatically collect and display metrics from the target. This lets you quickly verify the impact of your experiment without having to open an observability tool. For CPU experiments, you can see the amount of CPU load. For memory experiments, you can see RAM usage vs. capacity. For shutdown experiments, you can see when the target went offline.

Disabling experiment visualizations
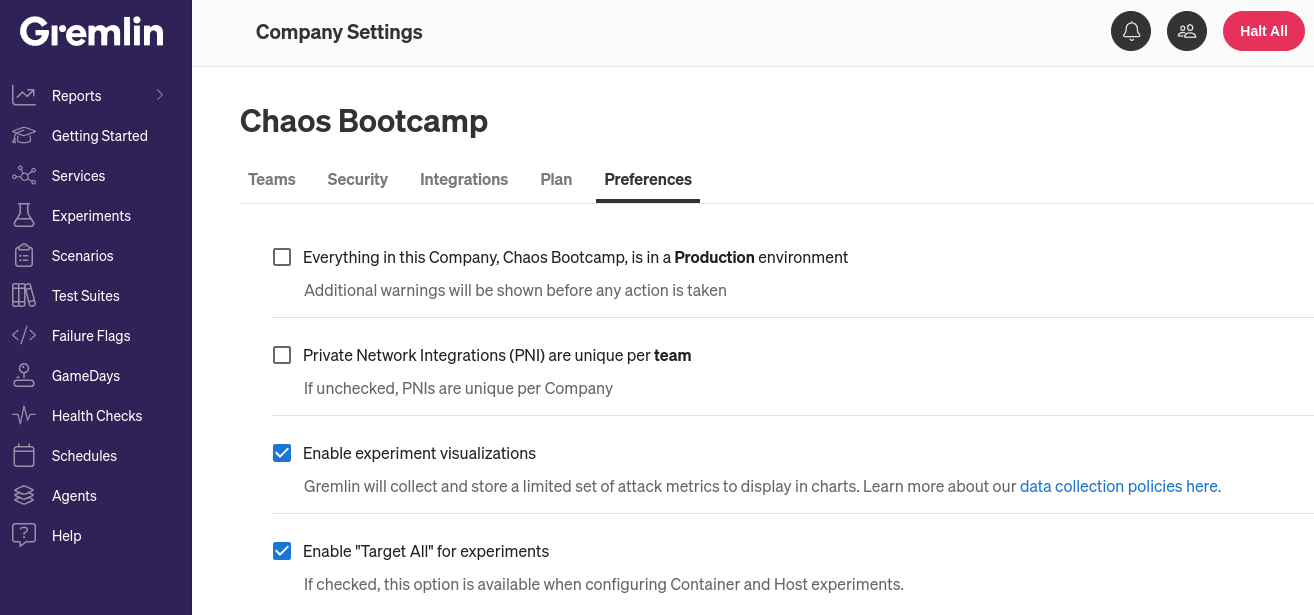
Experiment visualizations are enabled by default. Users with the Company Owner or Company Admin roles can disable them by going to the Company Settings page, clicking Preferences, and unchecking Experiment Visualizations. You can also view our data collection policy by clicking the link. Gremlin only collects metrics relevant to the experiment, and does not collect metrics when experiments are not running.
Disabling experiment visualizations for individual hosts
To prevent a host from sending metric data to Gremlin for visualization, open the configuration file for the Gremlin agent running on that host and add the line PUSH_METRICS=0. Then, restart the agent.
Scheduling experiments
Experiments can be run ad-hoc or scheduled, from the web app or programmatically. You can schedule experiments to execute on certain days and within a specified time window. You can also set the maximum number of experiments a schedule can generate.
Using agent tags
The Gremlin agent automatically detects certain metadata about the systems it’s running on. This metadata is made available in the form of tags. A tag is a simple key-value pair used to identify something about the system, like its hostname, public and private IP address, CPU architecture, and operating system. Gremlin can also find the cloud platform provider, region, availability zone, and other important information for systems running on cloud platforms like AWS.
Tags let you create groups of resources for experimentation. For example, instances in a Kubernetes cluster are automatically assigned a cluster tag with the name of the cluster as the value. Instead of having to remember which instances are part of the cluster, you can simply select the tag with the corresponding cluster name.
To learn more about tags, see Network Tags.
Creating custom tags
You can define custom tags in the agent configuration file. When configuring an experiment in the Gremlin web app, these tags will appear under the Other Tags category. For example, you can add this to your config.yaml file to create a tag with the name service and the value pet-store:
How experiments work
Every experiment in Gremlin is made up of one or more Executions. An Execution is an instance of the experiment running on a single target. An experiment can have multiple Executions if you’ve selected multiple targets to run it on.
Experiment stages
The Stage progression of an experiment is derived from the Stages of the experiment's Executions. Gremlin weighs the importance of each Execution’s Stage to determine the experiment's overall Stage.
Stages are sorted below by descending order of importance (i.e. the Running stage holds the highest importance):
As an example, an experiment with three Executions will derive its final reported stage by picking the most important stage from among its executions. So, if the three Execution Stages are <span class="code-class-custom">TargetNotFound, Running, TargetNotFound</span>, the resulting stage for the experiment will be <span class="code-class-custom">Running</span>.
Running experiments on Kubernetes
Gremlin allows targeting objects within your Kubernetes clusters. After selecting a cluster, you can filter the visible set of objects by selecting a namespace. Select any of your Deployments, ReplicaSets, StatefulSets, DaemonSets, or Pods. When one object is selected, all child objects will also be targeted. For example, when selecting a DaemonSet, all of the pods within will be selected.
Selecting containers
For State and Resource experiment types, you can target all, any, or specific containers within a selected pod. Once you select your targets, these options will be available under Choose a Gremlin on the Experiment page. Selecting Any will target a single container within each pod at runtime. If you've selected more than one target (for example, Deployment), you can select from a list of common containers across all of these targets. When you run the experiment, the underlying containers within the objects selected will be impacted.
Additional configuration options
This section lists common configuration options and how to use them. For details on experiment-specific parameters, check out the links to each experiment in the tables at the top of this page.
Including new targets in ongoing experiments
When selecting targets by tag, you have the option to check the Include New Targets checkbox. When this is checked, any newly-detected targets that meet the experiment's selection criteria will join the experiment. By default, new targets won't run the experiment, even if they match the criteria.
For example, imagine you want to run a CPU experiment on all EC2 hosts in the AWS us-east-1 region. When you run the experiment, AWS detects the increased CPU usage, automatically provisions a new EC2 instance, and installs the Gremlin agent. If Include New Targets is checked, Gremlin will add this new instance to the ongoing CPU experiment.
Specifying multiple network addresses and ports
You can specify multiple network addresses and ports using a comma-separated list. For ports, you can specify ranges by adding a dash between the lowest number and the highest number in the range (e.g. 3000-4000). This also applies to experiments run via the REST API and CLI.
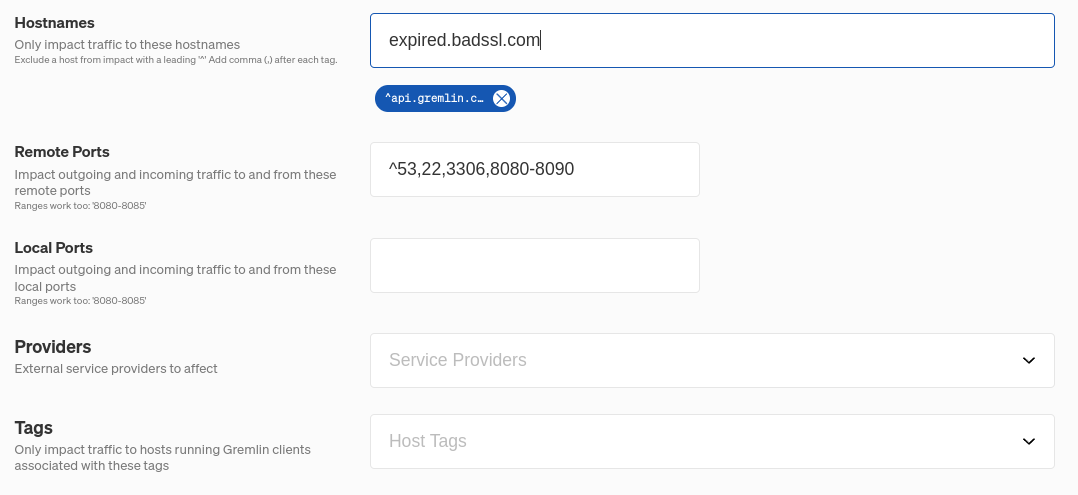
Excluding network addresses and ports
To exclude a hostname, IP address, or port from an experiment, add a caret ^ directly in front of it. For example, in the above screenshot, ^53 prevents DNS traffic from being impacted. This also works for ranges and CIDR values.
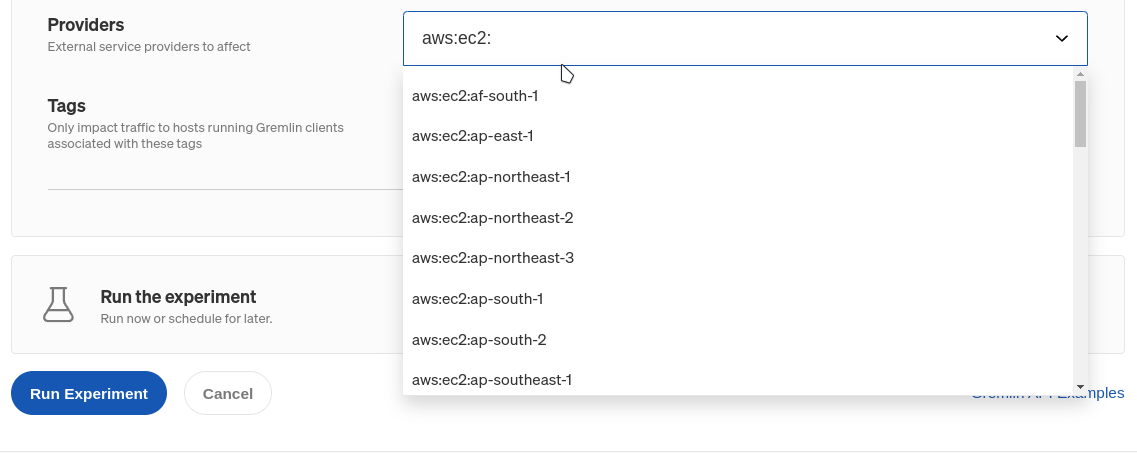
Targeting traffic to network provider services
For network experiments, Gremlin includes an easy way to target network traffic going to and from third-party service providers. When configuring a network experiment, click on the Providers drop-down and look for the service you want to impact. You can also search for services by typing in the box.
Specifying which network device to use during network experiments
All network experiments accept a --device argument that refers to the network interfaces to target. Starting with Linux agent version 2.30.0 / Windows agent version 1.9.0, you can specify one or more network interfaces using either a comma-separated list or with multiple --device arguments.
When unspecified, Gremlin targets all physical network interfaces as reported by the operating system. For virtual / cloud machines that typically includes the expected network interfaces like eth0 and eth1 for Linux and Ethernet for Windows.
Device discovery on older agents
Agents before Linux version 2.30.0 / Windows version 1.9.0 use a different strategy described here. All network experiments accept a --device argument that refers to the network interface to target. Gremlin network experiments target only one network interface at a time. When unspecified, Gremlin chooses an interface according to the following order of operations:
- Gremlin omits all loopback devices (determined by RFC1122).
- Gremlin selects the device with the lowest interface index that starts with
eth,en, or for Windows,Ethernet. - If nothing is found, Gremlin selects the device with the lowest interface index that is non-private (according to RFC1918).
- If nothing is found, Gremlin selects the first device with the lowest interface index.