Testing disaster recovery with Chaos Engineering


.svg)
.svg)

 This is an older tutorial
This is an older tutorialIntroduction
COVID-19 has changed daily life for everyone around the world. Social events were cancelled, governments issued stay-at-home orders, tens of thousands of businesses locked their doors, and telecommuting became the new normal for millions of workers.
During this time, digital services saw significant increases in demand, from media streaming to mobile banking to grocery delivery. In China, online penetration increased by 15–20%, while in Italy e-commerce sales for consumer products rose by 81% in a single week. Long-term growth plans may have been shelved in favor of short-term survival tactics, but the businesses best positioned to survive the pandemic were those that already had a plan in place, or were capable of pivoting quickly. This is particularly true since many of the spikes in online demand may not be temporary spikes, but permanent shifts in behavior.
If the pace of the pre-coronavirus world was already fast, the luxury of time now seems to have disappeared completely. Businesses that once mapped digital strategy in one- to three-year phases must now scale their initiatives in a matter of days or weeks.
Digital strategy in a time of crisis, McKinsey Digital
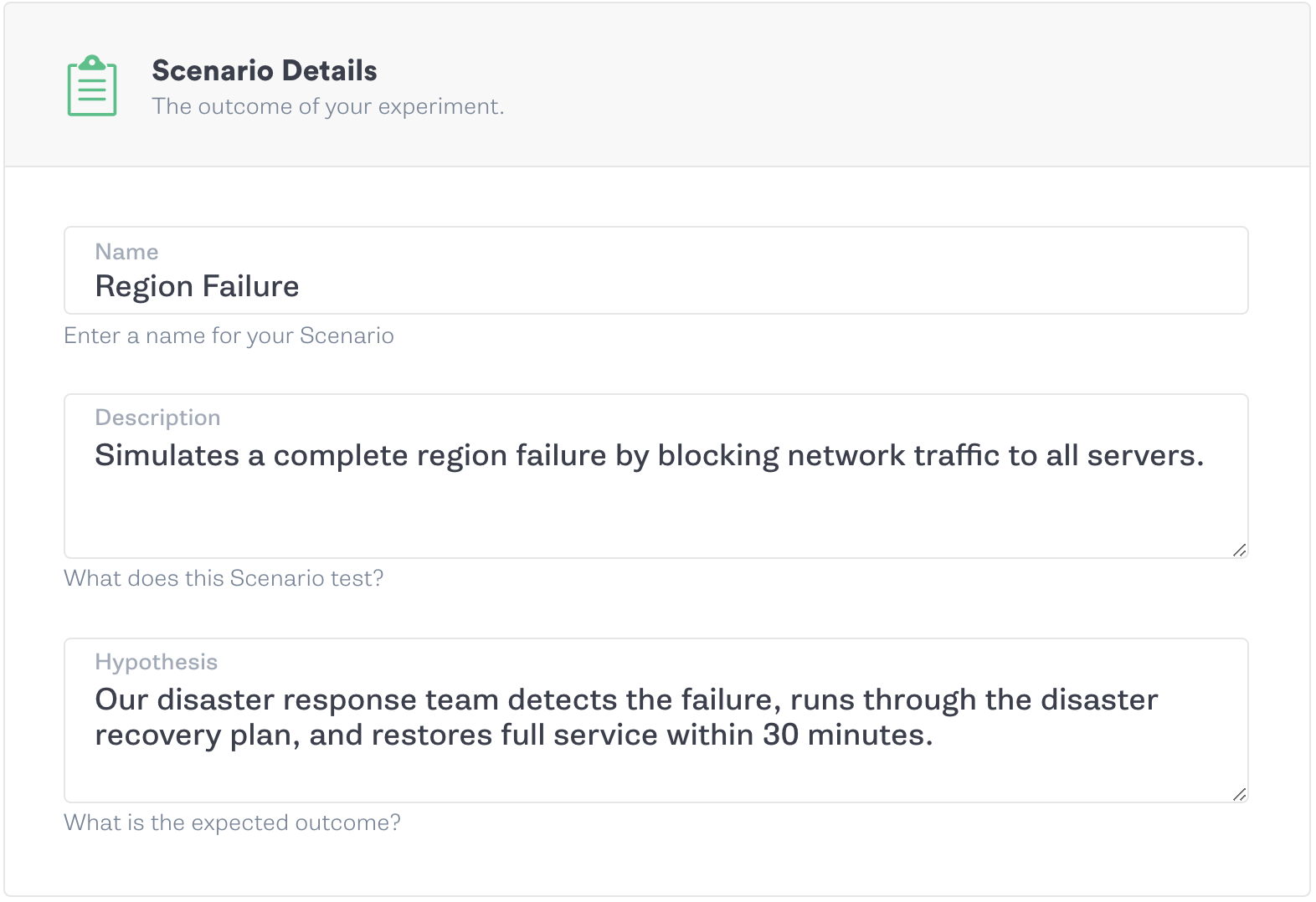
This outbreak underscores an important truth: disaster can strike at any time, and we need to be diligent about preparing for them. This means developing, testing, and maintaining disaster recovery initiatives. In this white paper, we explain the goal behind disaster recovery planning, how Chaos Engineering helps validate disaster recovery plans, and how we can use Gremlin to make sure we’re prepared for even the most unpredictable failures.
What is disaster recovery (DR) planning?
Disaster recovery (DR) is the practice of restoring an organization’s IT operations after a disruptive event, such as a natural disaster. It uses defined formal procedures for responding to major outages with the goal of bringing infrastructure and applications back online as soon as possible. Whether you’re making plans as part of a larger initiative such as failure mode and effects analysis (FMEA) or implementing DR outside of a structured mandate, the process involves:
- Identifying potential threats to IT operations
- Establishing procedures for responding to and resolving outages
- Mitigating the risk and impact of outages to operations
DR is a subset of business continuity planning (BCP). BCP focuses on restoring the essential functions of an organization as determined by a Business Impact Analysis (BIA), and DR is the subset of BCP that focuses on restoring IT operations.
A successful disaster recovery strategy involves recognizing the many ways that systems can fail unexpectedly, and creating detailed plans to streamline recovering from these failures. These are called disaster recovery plans or DRPs (also called playbooks or runbooks), and they provide step-by-step instructions for employees to follow during an incident in order to restore service.
While each DRP is different based on the organization and systems, generally the plans outline:
- The nature of the disaster
- Information about the systems such as server build documentation, architectural designs, and details about templates used for cloud server provisioning
- Any tools or services that can aid in the recovery process (such as backup tools)
- The team responsible for recovering the failed systems
- Protocols for communicating with team members and documenting recovery steps
Many companies maintain DRPs as a requirement of IT service management (ITSM), or as checklists to help with regular maintenance task delegation and onboarding new team members. DRPs are also commonly used in site reliability engineering (SRE) as playbooks, which instruct engineers on how to respond to alerts and incidents. In all cases, they are meant to reduce stress, reduce time to resolution, and mitigate the risk of human error when restoring systems to a fully functioning state.
Why do we need disaster recovery planning?
With each year, our organizations grow more (never less) reliant on technology. Not only do we rely on technology to serve customers, but also to perform normal business operations. If any systems go down unexpectedly, it threatens our ability to generate revenue or even operate at all.
One of the primary goals of IT is to keep systems up and running for as long as possible. This is known as high availability (HA), and it’s achieved using strategies such as distributed computing and replication. While HA is important, it does not account for black swan events, which are events that impact our applications and systems in ways that are extremely difficult to predict, such as natural disasters. These can have severe consequences for our systems including system outages, hardware failures, and irrevocable data loss. As a result, our organization faces:
- Financial losses due to an inability to serve customers
- High costs associated with restoring systems and data
- Lost productivity while engineers resolve the issue
- Damage to reputation
Because black swan events are inherently unpredictable, we can’t prepare for every possible threat. Instead, we must identify the ways our systems can fail and develop strategies to restore them to full service when these failures happen. Disaster recovery planning helps us accomplish this, but even with a well-designed DRP in-hand, we need a way to verify its efficacy before a black swan event occurs. This is where Chaos Engineering helps.
How Chaos Engineering helps in disaster recovery planning
Chaos Engineering is the practice of systematically testing systems for failure by injecting small amounts of harm. We do this by running chaos experiments, in which we carefully and methodically inject harm into our systems. A chaos experiment involves running an attack against a specific system, application, or service. This can include adding latency to network calls, dropping packets on a specific port or network interface, or shutting down a server.
Chaos Engineering is often used in site reliability engineering (SRE) to test and improve a system’s reliability. Because SREs often handle system failures, many of their practices overlap with those used in DR. For example, runbooks (also called playbooks) behave much like DRPs by providing engineers with detailed instructions on how to restore service after an incident. Teams validate their runbooks by performing FireDrills, which are deliberately created outages meant to test runbooks under realistic—but controlled—circumstances. Many teams also use GameDays in which teams reproduce past incidents in order to test the resilience of their systems.
In the context of disaster recovery, we can use Chaos Engineering to recreate or simulate a black swan event. This gives us the opportunity to test our DRP and our response procedures in a controlled scenario, as opposed to recreating disaster-like conditions manually or waiting for a real disaster. As the world’s first enterprise Chaos Engineering platform, Gremlin allows teams to run chaos experiments in a safe, simple, and secure way. Gremlin provides a comprehensive set of application and infrastructure-level attacks that we can use to recreate real-world outages, letting us fully test our response procedures without putting our systems at risk.
Next, we’ll look at how to develop a DRP, and how we can use Chaos Engineering to test and validate our plan.
How to create and validate your disaster recovery plan
While every DRP is company and situation-specific, creating and validating one involves four stages:
- Listing critical assets and their level of importance to operations.
- Identifying the risks and threats posed to those assets.
- Detailing the steps needed to replace assets after a failure.
- Testing and applying the plan to ensure it works as expected.
We’ll explain each stage in greater detail in the following sections.
Identifying critical assets
The first step in disaster recovery planning is to inventory our applications and systems along with their essentiality. This will help us quickly identify and prioritize systems that need to be recovered or restored after a black swan event.
One approach involves assigning each asset a priority level, which indicates how essential the asset is to business operations. Mapping systems in this way clearly identifies their importance so that engineers can quickly determine which systems to restore first after a black swan event. We start by identifying our business-critical systems, such as those that generate revenue or provide essential services. From there, we identify any services that these assets depend on. These dependencies are our priority 0 (or P0) systems and should be given top priority during recovery. Each step in the dependency chain is assigned a higher priority number (P1, P2, etc.), which corresponds to a lower criticality. For example, a P0 system should be restored before a P2 system, since it could be a potential dependency of other P0, P1, or P2 systems.
During this step, we should also identify any systems that don’t have any DR or high availability mechanisms in place. This includes systems that:
- Host mission-critical applications, services, or data, or
- Lack comprehensive automated backup or recovery processes, or
- Lack redundancy or replication.
Not all of these systems will be P0, but they are still high-risk. If possible, we should implement some sort of protection on these systems before continuing with disaster recovery planning, whether through automated backups or replication.
Assessing risks and threats
Now that we’ve taken stock of our systems, we need to consider the various ways that they can fail, the impact these failures will have on our business, and how we can recover from them. Remember that black swan events are both unpredictable and severe, and can include:
- Natural disasters such as fires, floods, and earthquakes.
- External system failures, such as widespread Internet outages and power failures.
- Third-party provider outages (i.e. loss of infrastructure owned by a third-party cloud provider).
- Human-created failures such as malicious actors, unauthorized employees, and cybersecurity breaches.
The nature and severity of the event will influence our planning process and estimated recovery time, which is why teams will often create multiple DRPs covering different scenarios.
In order to determine how effective our DRP is, we need a way to measure the recovery time. We do this primarily using two key metrics: recovery time objective (RTO) and recovery point objective (RPO).
Recovery Time Objective (RTO)
Recovery time objective (RTO) is the measure of how quickly systems become operational after a failure. It is a target recovery time, or the maximum amount of time we’re willing to tolerate being down. Our true recovery time after an event is measured by the recovery time actual (RTA). In site reliability engineering (SRE), this is commonly called the time to recovery (TTR), with the mean time to recovery (MTTR) being an average of the RTA across multiple outages.
In an ideal scenario, our RTO and RTA will be zero, meaning we can restore service immediately after a failure. This is the goal of organizations that provide critical services such as financial firms, government agencies, and healthcare organizations. However, a low RTO is both expensive and technically complicated to implement correctly, requiring not only automated failover and replication solutions, but also monitoring systems that can immediately detect and respond to outages. In reality, the RTA and RTO can vary significantly and range from a few minutes to several days, depending on the severity of the event.
Recovery Point Objective (RPO)
The recovery point objective (RPO) is the amount of data loss or data corruption that we’re willing to tolerate due to an event. This is measured by the difference in time between our last backup and the time of the failure, at which point we assume that any data stored on the failed system is lost. The actual amount of data loss is measured by the recovery point actual (RPA).
As with RTO, we want our RPO and RPA to be as close to zero as possible, meaning we don’t lose any data. However, this is also difficult to implement realistically. For example, GitLab, a popular source code management and CI/CD tool, accidentally deleted data from their production database during one incident. While they had multiple backups, nearly all of their recovery attempts were unsuccessful, resulting in a six-hour outage (RTA) and the loss of over 5,000 projects, 5,000 comments, and 700 user accounts (RPA).
Reducing our RPO means creating more frequent backups—or replicating continuously—to an offsite location, which greatly increases our operating costs and complexity. When choosing our RPO, we’ll need to balance the costs of losing production data against the costs of replicating and backing it up.
Creating a recovery plan
A DRP must contain all of the information and instructions necessary for engineers to restore systems to their normal operational states, while simultaneously minimizing the impact on the business. The plan should be comprehensive enough to guide engineers through the entire recovery process, while keeping the RTA as low as possible.
The contents of a DRP should include:
A high-level overview or outline of the steps involved in the plan.
- A list of employees, teams, or roles involved in the recovery process, including contact information. If the point-of-contact changes (e.g. you have a rotating on-call team), provide a way for employees to find out who is currently on rotation and how to contact them.
- An inventory of assets along with their priority level.
- Detailed information about any DR systems currently in place such as backup tools, failover systems, redundancy, and replication systems. We should also inform engineers of any automated processes that might have triggered so they can accurately determine the current state of our systems.
- Clear instructions on how to access, retrieve, and restore backups; how to verify that the restoration process was successful; and what to do if a restoration fails.
- How to check for any secondary or failover systems that were activated, and how to switch traffic back to primary systems once service is restored.
- How to access observability tools for troubleshooting and root cause analysis.
This isn’t an exhaustive list, but rather a starting point. The goal of the DRP is to provide a clear, comprehensive, and easy-to-follow set of instructions for engineers so that they can restore service as quickly as possible.
How different DR methods affect planning
When writing our DRP, we first need to identify the disaster recovery systems that are already in place. These influence everything about our DRP, from our RTO and RPO to the required recovery steps.
The ideal backup architecture is an active-active architecture, where we operate an identical replica of our production systems in an offsite environment. Running two separate replicated instances of the same systems lets us continue operations by immediately failing over to the secondary environment while we restore the primary, resulting in zero RTO and RPO. However, this adds technical complexity to our deployment and effectively doubles our operating costs.
A similar architecture is active-passive, where the secondary (passive) environment only begins operating when the primary (active) environment fails. Data is still replicated between both environments, but the systems running our applications remain idle in the secondary until they are needed after an event. This reduces our costs, but can increase both the RTA and RPA as engineers need extra time to bring the secondary environment online.
The type of architecture you use will influence your recovery plan, particularly the steps needed to come back online. In active/active setup, recovery might be as simple as changing a DNS entry. An active/passive setup might involve changing DNS entries, spinning up idle hardware, copying data, and more, costing us valuable time
Testing the plan
A DRP can’t be relied on until it’s been proven to work. While the most effective way to validate a DRP is to wait for a black swan event, this is also the most risky. We can test our DRP in a much less risky manner by using Chaos Engineering to recreate conditions that would be present during a disaster—such as server outages and network failures—without causing permanent or irreversible damage to our systems. This allows us to test our DRP much more safely and much more predictably than we could otherwise.
For example, Qualtrics is an Experience Management platform that has invested heavily in disaster recovery in order to mitigate the risk of downtime. As part of their disaster recovery planning process, they needed to test large-scale disaster recovery activities—like region evacuation—without actually performing a hard failover. Using Gremlin, over 40 of their teams independently planned for failover, which saved over 500 engineering hours and reduced their per-dependency test times from several hours to just four minutes. Qualtrics still did the full scale DR test to be sure the plan worked properly, but using Gremlin to test each team independently helped them save time in the preparation for this exercise.
In the next section, we’ll show how Chaos Engineering can be used to validate a DRP by running through a mock FireDrill. Recall that a FireDrill is a planned event where we deliberately induce failure in order to test our response procedures. We’ll use Gremlin to simulate a regional outage, resolve the issue using a DRP, then do a post-mortem to determine whether our DRP was successful.
Building confidence in testing disaster recovery
Running FireDrills is the best way to ensure that your DRPs are effective, but if you’re just starting out on your disaster recovery or Chaos Engineering journey, this may feel like a significant and risky step. If you don’t yet feel confident recreating a black swan event, start with a small-scale chaos experiment, such as blocking traffic to a specific application instead of an entire production cluster. As you become more confident in your ability to recover from small-scale failures, incrementally increase the intensity of the attack (the magnitude) and expand it across a larger number of systems (the blast radius).
Gremlin allows you to quickly and safely halt and roll back any ongoing experiments in case of unexpected circumstances. This greatly reduces the risk of an experiment causing actual harm to your systems. If you find that you need to halt an experiment while testing a DRP, make sure to document the reason so that you can integrate it into your DRP, or so that your engineers can address the root cause.
A real incident is a true test and the best way to understand if something works. However, a controlled testing strategy is much more comfortable and provides an opportunity to identify gaps and improve.
Lorraine O'Donnell
Global Head of Business Continuity at Experian [via CIO.com]
Validating the plan by running a FireDrill
Now we’re ready to create a chaos experiment and validate our DRP. Let’s assume that our company manages an e-commerce platform that sells to customers around the world. Every minute of downtime amounts to hundreds of thousands of dollars in lost sales, and any data loss or corruption can result in unfulfilled or inaccurate orders. To reduce the risk of data loss, we maintain an active/passive architecture with continuous replication to a separate data center or region. We’ll set an RTO of 30 minutes: not unrealistically short, but not so long that it creates an extended outage.
Before starting the FireDrill, we need to notify key stakeholders in our company. These are the executives and engineering team leads who aren’t directly involved in the recovery process, but will still be alerted of any major incidents, such as the Chief Technology Officer (CTO) and Director of Engineering. We want our on-call engineers to believe that this is a real incident as it will provide the most accurate evaluation of our DRP, but we want to notify stakeholders in order to prevent the outage from escalating into a full-blown emergency response.
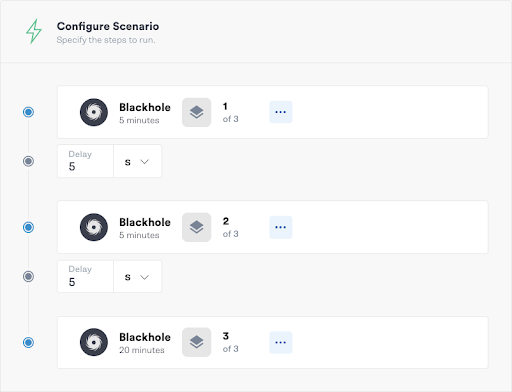
To simulate our disaster conditions, we’ll create a Scenario in Gremlin. Scenarios let us accurately simulate real-world disaster conditions by incrementally increasing both the blast radius and magnitude of an attack. In this example, we want to simulate losing a data center or region consisting of three servers. We’ll do this by using a blackhole experiment ,to block all incoming and outgoing network traffic on each server for the duration of the Scenario. A shutdown experiment would provide a more realistic simulation, but we can immediately stop a blackhole attack at any time, making it the safer option for teams starting out with DR.
In addition to dedicated halt buttons, Gremlin also has multiple fail-safes built-in in case our Scenario gets out of hand. For one, attacks will only run for the amount of time specified (30 minutes in this example). If we can’t restore service within that time, the attack ends and the servers resume normal operations. Attacks will also immediately halt if the Gremlin agent loses connection to the Gremlin Control Plane.
The Scenario has three stages. First, one of the servers is immediately taken offline. After five minutes, we expand the blast radius to a second server. After another five minutes, we expand the blast radius again to the final server, taking all three servers offline. Once 30 minutes has passed from the start of the experiment, the Scenario ends and all three servers resume normal service.
During the Scenario, we want to track our:
Scenario start and end times. Gremlin automatically tracks and records these.
- Time to detection (TTD) and time to execution (TTE): how long it takes the team to realize there’s a problem and start following the DRP.
- RTA: how long it takes for the team to run through the plan and fully restore service.
Once we start the Scenario, the following process should occur:
- Our monitoring and alerting solution detects a problem and notifies the disaster recovery team. The difference in time between the start of the Scenario and the disaster recovery being notified of the problem is our time to detection (TTD).
- The team starts following the DRP, giving us our time to execution (TTE).
- If we successfully restore service, we can end the Scenario and record our actual recovery time (RTA).
- If we fail to restore service, the Scenario ends and our systems automatically resume normal operation.
- We compare the time of the backup we restored from to the Scenario start time (i.e. the time that our systems were taken offline), giving us our recovery point (RPA).
Once the Scenario ends and we’ve restored service to our primary systems, the next step is to gather our observations from the FireDrill and evaluate the success of our DRP.
Post-mortem: How to tell if your DR plan was successful
Every black swan event and DRP execution should be followed by a post-mortem, where we review our processes to determine their success. In addition to gathering key metrics such as RTA and RPA, we want to know how easy or difficult it was for the response team to follow the DRP. Our analysis should answer the following questions:
- Were we able to successfully restore service?
- How long did it take our monitoring and alerting systems to detect the issue (TTD)?
- How long did it take for the response team to start following the DRP (TTE)?
- How long did it take to restore our systems to full operation (RTA), and how does this compare to our RTO? Can we reduce our RTA by optimizing or automating parts of our DRP?
- How much data loss did we experience (RPA), and how does this compare to our RPO? Are there any steps we can take to reduce our RPA, such as increasing our backup frequency?
- What impact did the restoration have on our systems? Did our level of service change? Were any of our systems unrecoverable?
- What did the restoration process cost us in terms of recovery expenses, operating expenses, engineering effort, and lost revenue?
It’s unlikely that a DRP will work flawlessly on the first try. An unsuccessful FireDrill doesn’t necessarily mean that the team failed, but rather that there’s a shortcoming in our plan or procedures that we need to address. Identifying these shortcomings is why we do these exercises! We can use our experience to find ways to improve, optimize, or fix parts of our plan, or by improving our backup and recovery systems. An "unsuccessful" recovery is beneficial because it lets us find and fix problems before we ever face a real emergency.
When determining how to improve our DRP, we should consider:
- Which actions were necessary for restoring service? Were there any steps that are no longer relevant, or were skipped entirely? If so, can we remove them from the plan or automate them?
- How closely did our team adhere to the plan? Did everyone understand their role and how to communicate? Was there any confusion over who was responsible for what processes?
- How confident did the team feel about following the plan? Were there any steps that they were hesitant or unable to complete? If so, we should provide additional opportunities for practice and training, such as holding more frequent FireDrills.
- How close (or far) were we to our RTO and RPO? Do we need to change our backup and recovery strategy to better meet these objectives?
Over time, IT infrastructure and business processes change, necessitating changes to our DRPs. If we don’t maintain our plans, procedures that worked well in the past may no longer be effective or even relevant. A DRP is effectively a living document that requires frequent updating and testing, otherwise it no longer suits its purpose. We should encourage our teams to not only document any infrastructure changes, but also run periodic FireDrills to validate our plans.
Conclusion
Today’s computer systems are far more complex and dynamic, creating more opportunities for failure. It’s no longer enough to wait for an incident to strike before implementing and testing our disaster recovery plans. With Chaos Engineering, we can proactively validate our plans to ensure business continuity even when faced with a catastrophic and damaging outage.
If you’re getting started with business continuity planning and disaster recovery planning, consider looking into a standardized procedure such as ISO 22301 Business Continuity, ISO 31000 Risk Management, or the Failure Modes and Effects Analysis (FMEA) method.
Avoid downtime. Use Gremlin to turn failure into resilience.
Gremlin empowers you to proactively root out failure before it causes downtime. See how you can harness chaos to build resilient systems by requesting a demo of Gremlin.

.svg)