How to test your High Availability (HA) Kubernetes cluster using Gremlin


.svg)
.svg)

Introduction
In this tutorial, you'll learn how to validate the resiliency of your Highly Available (HA) Kubernetes cluster using Gremlin. We'll walk through provisioning an HA cluster with three control plane nodes, deploying the Gremlin Kubernetes agent, running a Shutdown attack to terminate one of the nodes, then testing the cluster to ensure it's still operational.
By reading this tutorial, you'll learn how to test whether your Kubernetes cluster is truly Highly Available and can withstand a control plane node failure.
Want more? Check out our comprehensive eBook, "Kubernetes Reliability at Scale."
Overview
This tutorial will show you how to:
- Step 1 - Deploy a Highly Available Kubernetes cluster
- Step 2 - Deploy the Gremlin Kubernetes agent
- Step 3 - Run a Shutdown attack on a control plane node
Background
Control plane nodes play a critical role by running the services that manage, monitor, and maintain the state of the Kubernetes cluster. This includes the API server, etcd, the scheduler, and the controller manager. If a cluster only has one control plane node and it fails, the operation and stability of the cluster could be severely impacted. Highly Available (HA) clusters address this by letting you run multiple control plane nodes simultaneously, and while this doesn't eliminate the risk, it does significantly reduce its likelihood.
However, there's still a lot that can go wrong here. What if the cluster uses an external etcd cluster that isn't set up for high availability? What if the load balancer isn't configured properly and continues routing traffic to the failed node? What if the cluster enters a split-brain state? We'll want to consider these scenarios in advance and test them in order to better understand how our cluster handles failure.
We'll use Gremlin to test these scenarios by introducing fault into a control plane node, observe how our cluster responds, then use these insights to determine whether our HA cluster is resilient.
Prerequisites
Before starting this tutorial, you'll need the following:
- A Gremlin account (sign in or request a demo).
- The kubectl command-line tool.
- The Helm command-line tool.
- A Highly Available Kubernetes cluster (if you don't already have a cluster, continue to step 1, otherwise skip to step 2).
Step 1 - Deploy a Highly Available Kubernetes cluster
First, we need to create an HA cluster. If you already have a cluster provisioned, skip ahead to step 2.
There are multiple options for creating an HA cluster, including:
- Using kubeadm to manually create a cluster.
- Using Kubernetes in Docker (kind) to simulate a multi-node Kubernetes cluster within Docker.
- Deploying minikube, K3s, or a similar Kubernetes distribution to your local machine or to a cluster of virtual machines.
Here's a tutorial that walks through setting up an HA cluster on Digital Ocean using K3s. Once your cluster is deployed, you can confirm that it's an HA cluster by running <span class="code-class-custom">kubectl get node --selector='node-role.kubernetes.io/master' </span>. If this returns more than one entry, then the cluster has multiple control plane nodes and is highly available:
Step 2 - Deploy the Gremlin Kubernetes agent
In order to use Gremlin to run attacks on our Kubernetes cluster, we'll need to install the Gremlin Kubernetes agent. This allows Gremlin to detect resources such as Pods, Deployments, and DaemonSets, and select them as targets for running attacks and Scenarios. The easiest way to install the agent is using Helm.
First, add the Gremlin Helm repo:
Next, create a new namespace:
Finally, install the agent. Make sure to replace <span class="code-class-custom">$GREMLIN_TEAM_ID with your actual team ID</span>, <span class="code-class-custom">$GREMLIN_TEAM_SECRET</span> with your team secret key, and <span class="code-class-custom">$GREMLIN_CLUSTER_ID</span> with a uniquely identifying name for this cluster. You can learn more about retrieving your team ID and secret keys in the Authentication documentation.
By default, the Gremlin agent won't let you run attacks on control plane nodes. This is by design, and is meant to prevent accidentally terminating a control plane node. To change this, we'll need to add some additional parameters to the end of the Helm command to allow scheduling Gremlin onto master nodes:
Once you deploy the Helm chart, you can confirm that the deployment succeeded by logging into your Gremlin account, opening the Clients page, then clicking the Kubernetes tab. Your cluster will be listed with the name that you entered for <span class="code-class-custom">$GREMLIN_CLUSTER_ID</span> :
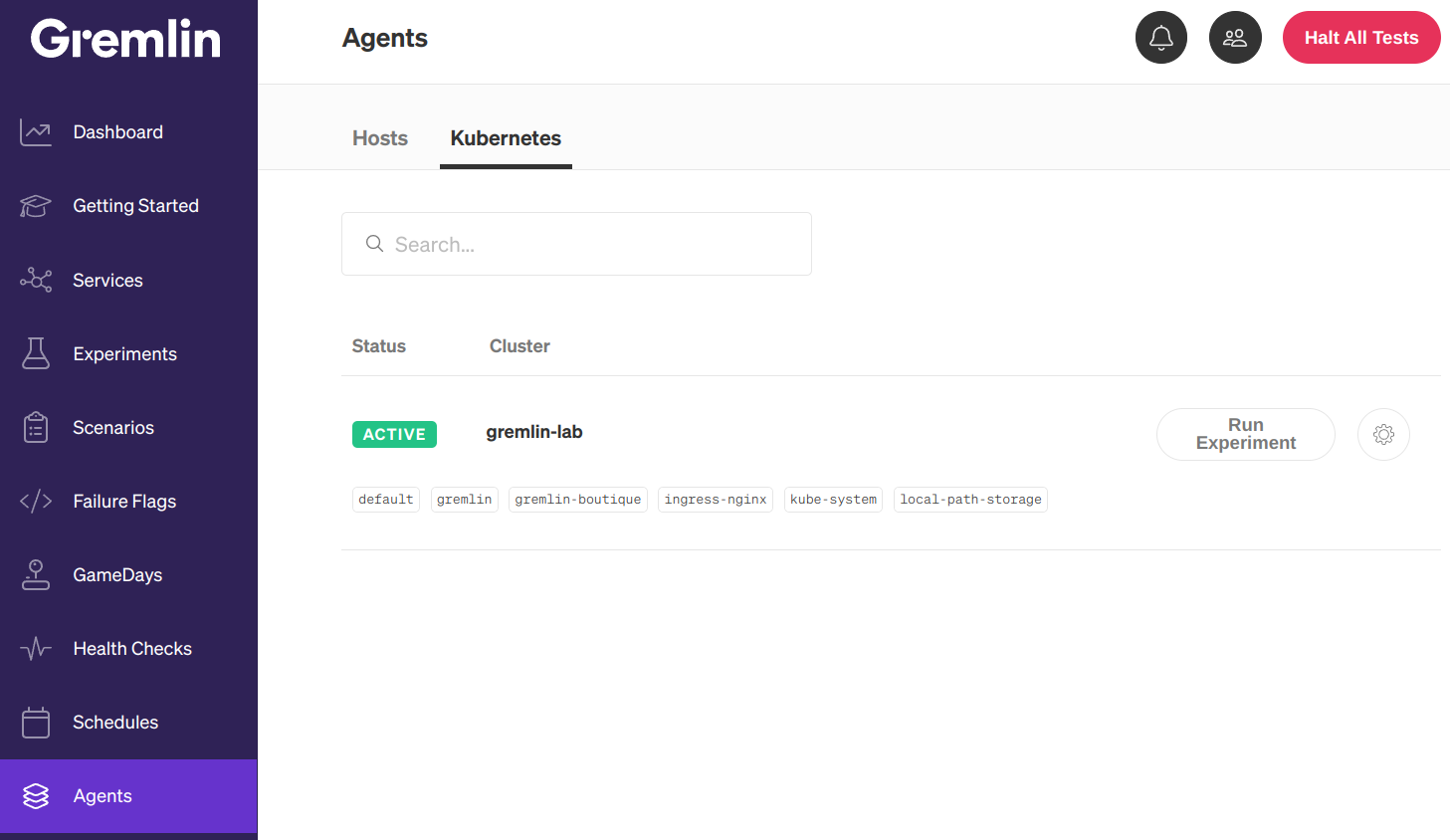
Step 3 - Run a shutdown experiment on a control plane node
Now, let's run our experiment. Remember, we want to determine whether our Kubernetes cluster continues operating when one of the control plane nodes fails. To do this, we'll run a Shutdown attack to shut down one of the nodes, then check the integrity of the cluster by interacting with the Kubernetes API.
In the Gremlin web app, select Attacks on the left-hand navigation pane, then select New Attack. Select the Infrastructure tab and make sure Hosts is selected. Next to Choose Hosts to target, select the Exact tab. You'll see each of your control plane and worker nodes listed. Click the check box next to one of your control plane nodes to select it as the attack target.

Next, scroll down to Choose a Gremlin and click to expand it. Select the State category, then select Shutdown. Change the value of the Delay field to <span class="code-class-custom">0</span> , then uncheck Reboot. Finally, click Unleash Gremlin to start the attack.
While the attack is running, check the state of your cluster using the Kubernetes Dashboard or a cluster management/monitoring tool like K9s. Alternatively, you can simply refresh kubectl using the <span class="code-class-custom">watch</span> command. For example, the following command updates the status of your control plane nodes every second:
After a few moments, we'll see one of our nodes (gremlin-lab-control-plane3) report as <span class="code-class-custom">NotReady</span>:
While the node might be down, the fact that we're able to see this information implies that the control plane as a whole is still available, and therefore the cluster is still up and running. We might not be able to use that specific node, but we can still use the other two nodes to manage the cluster. We've just confirmed that our cluster is highly available and can tolerate a control plane node failure!
Conclusion
We confirmed that our Kubernetes cluster is actually highly available and can withstand losing a control plane node without also losing cluster integrity. If we wanted to demonstrate an even higher level of resiliency, or test for situations like a split-brain cluster, we can repeat this attack and increase the blast radius by running it on two or more nodes simultaneously.
As an alternative to the Shutdown attack, we could instead run a Blackhole attack. Blackhole attacks drop all outbound network traffic from the target(s), making it appear as if it's offline without actually shutting it down. A key benefit over the Shutdown attack is that once the Blackhole attack ends or is halted, the impact of the attack reverts immediately and the node resumes its normal operation without you having to restart or reconnect it.
As one final takeaway, consider the possibility that multiple control plane nodes could fail within a short time frame. If more than half of your control plane nodes fails, this could lead to a split-brain situation, or even a cascading failure. If one node fails and its traffic is diverted to another node that's unequipped to handle the sudden surge, this can cause the second node to fail.
We can replicate this by using a Scenario, which is a Gremlin feature that lets us run a series of attacks sequentially. This Scenario could start with one Blackhole attack targeting a single node, then run a Blackhole attack targeting two nodes, and so on. Gremlin comes with a built-in Scenario designed to test this specific use case. Click on the card below to open the Scenario in the Gremlin web app and try it out on your cluster:
As hosts fail, shutdown, or are taken offline, their workload will be distributed without users noticing any effects and there will not be any errors thrown.
Length:
3 steps
Attack Type
Shutdown
.svg)
Avoid downtime. Use Gremlin to turn failure into resilience.
Gremlin empowers you to proactively root out failure before it causes downtime. See how you can harness chaos to build resilient systems by requesting a demo of Gremlin.

.svg)