
The AI (artificial intelligence) landscape wouldn’t be where it is today without AI-as-a-service (AIaaS) providers like OpenAI, AWS, and Google Cloud. These companies have made running AI models as easy as clicking a button. As a result, more applications have been able to use AI services for data analysis, content generation, media production, and much more.
However, under the shiny exterior, AI models are like any other software dependency: they can crash, throw errors, and lose network connectivity. Worse, these failures can cascade up the rest of your application and cause unexpected impacts. How do you prepare for this, and more importantly, how do you verify that you can handle AI failures before they impact your customers? We’ll answer all of these questions in this blog.
What is AI-as-a-Service, and how does it work?
Running AI models is difficult, complex, and prohibitively expensive for many organizations. Even just setting up a compute instance or cluster for AI is excessive for teams that only need basic generative AI or analysis features.
AIaaS providers meet these needs by hosting models so you can focus on using them in your applications. Providers typically offer a web interface, API interface, and SDKs that you can use to send queries to a model and receive responses. OpenAI, for example, has dozens of official and community-made libraries for popular programming languages and development frameworks.
How can AIaaS services fail?
No matter which provider or method of interaction you choose, they all have one thing in common: they require active network connections to the provider’s backend systems. This is called a dependency. If a connection becomes unavailable due to a failure, then you can no longer access your AI model, and your queries will most likely fail. This is called a dependency failure: a service you depend on has a failure, impacting the reliability of your own applications.
There are a few ways AI-as-a-service providers can fail. This isn’t an exhaustive list, but it covers the broader categories of failure:
- Complete failure: The AIaaS provider has a complete outage, or the connection between your systems and your provider fails in a way that you can’t route around.
- Latency: You can connect to the provider, but poor network conditions add a significant amount of latency to interactions.
- Certificate expiration: Your provider did not rotate or update its TLS certificates before they expired, resulting in “insecure connection” error messages and failed API calls.
For this blog, we’ll focus on complete failures. The unfortunate tradeoff with cloud services is that you have no control over their reliability. If the service becomes unavailable, you’re stuck until the provider resolves the issue. But while it’s the provider’s responsibility to prevent failure as much as possible, it’s your responsibility to ensure your applications keep working even if the provider is down.
How do you make your AI-powered services more resilient?
The first step is detecting failures when they happen. This usually means adding logic around your API calls to your AI provider.
The circuit breaker technique, for example, is a great example of this. Circuit breakers track the number of attempted calls made to an API. If enough calls fail, the circuit breaker trips, preventing any other calls from being made to the API. After a set time, the circuit breaker allows requests to go through to test whether the API is available, and if the requests succeed, the breaker closes, otherwise, it remains open.
Some provider libraries have built-in error handling logic. For example, OpenAI’s Node.js library has a circuit breaker that retries twice before tripping, times out after 10 minutes (by default), and throws an APIError when it can’t connect. Make sure to check your provider’s SDK before implementing your own error handlers.
Once you’ve detected the error, you can implement alternative routes and fallback mechanisms, such as:
- Redirecting prompts to a different AI provider.
- Answering prompts using cached responses.
- Displaying an error message and asking the user to try again later.
Redirecting requests to a backup AIaaS provider isn’t always possible, especially when your queries require context (e.g. when querying a model that uses retrieval-augmented generation (RAG)). Still, it’s better than not handling users' queries at all or using answers that may be out-of-date.
Making your AI services more reliable with Gremlin
Gremlin lets you test the resiliency of your services by simulating failures in AI-as-a-service dependencies. Instead of waiting for your provider to have an outage, you can use Gremlin to recreate outage conditions, observe how your services respond, and use that information to build resilience.
When you add a service to Gremlin, Gremlin automatically detects the service’s dependencies based on the DNS queries it makes. For each dependency, Gremlin creates three different tests (using the default Gremlin Recommended Test Suite):
- A Failure test, which simulates a network outage.
- A Latency test, which injects 100ms of latency to all network traffic to the dependency.
- A Certificate Expiry test, which checks the dependency’s TLS certificate chain for any certificates expiring in the next 30 days.
For example, let’s use a basic large language model (LLM)-powered chat setup. In this setup, we have AnythingLLM as the chat frontend and Ollama as the LLM engine. These services are running on a Kubernetes cluster in separate deployments. Gremlin natively supports Kubernetes, which means we can run reliability tests on one deployment without impacting the other. This is ideal for testing how AnythingLLM responds to problems with Ollama.
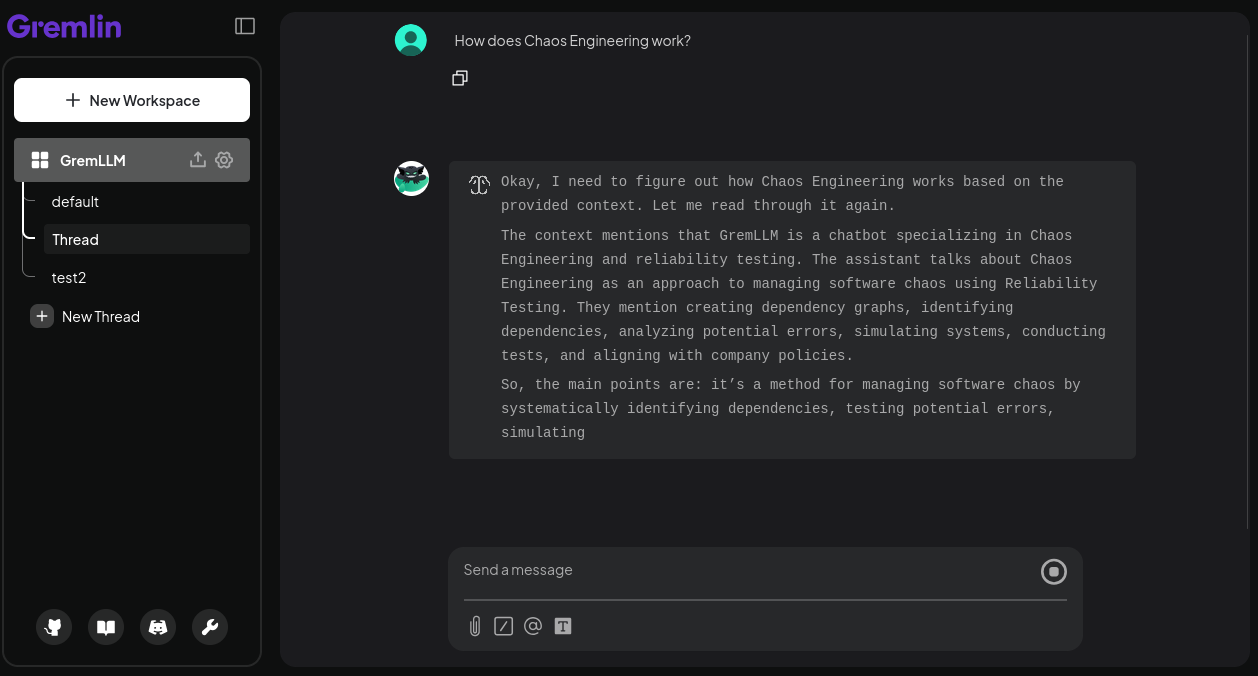
Normally, this works just like you’d expect. You can use AnythingLLM to download models for Ollama and send queries. Ollama will stream the response back to AnythingLLM, where it’s rendered onto the page:
Testing AI dependency failure
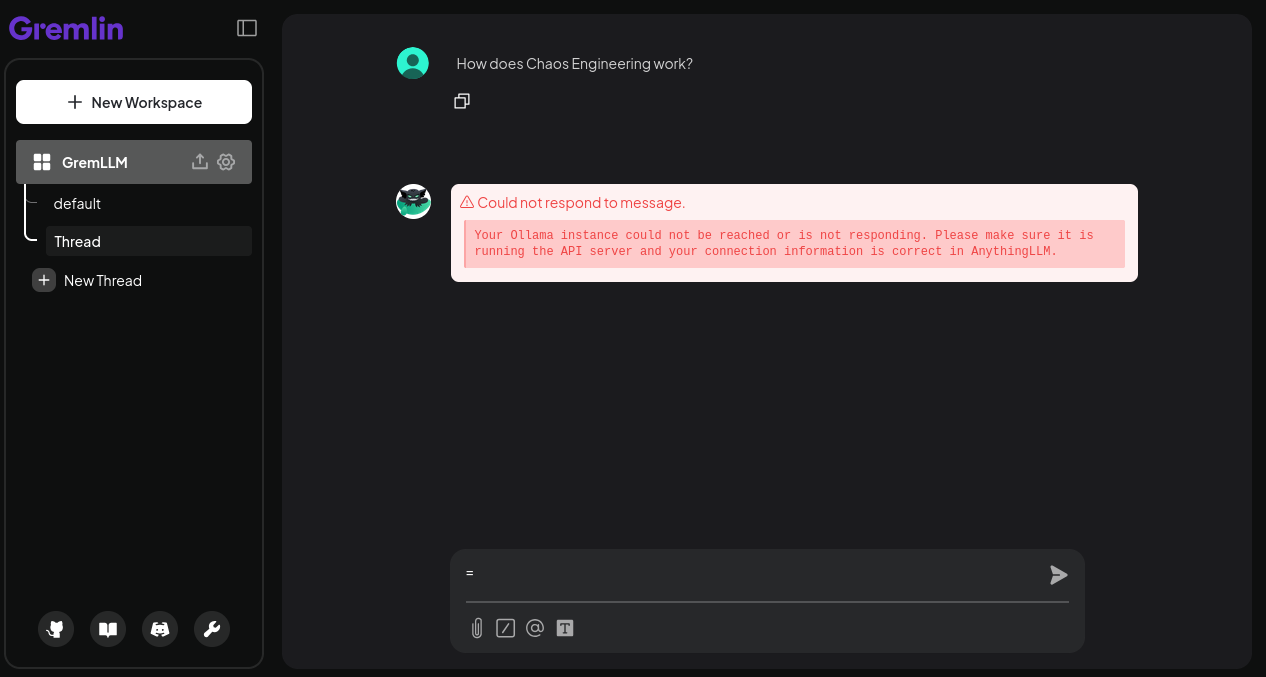
Ollama is both a direct dependency and a single point of failure for AnythingLLM. So what happens if Ollama isn’t available? Let’s run a network blackhole experiment and see.
In the Gremlin web app, you can start a one-off experiment by going to Experiments, then + Experiment. Gremlin supports many target types, mainly hosts, containers, and Kubernetes resources. We can directly select AnythingLLM’s Kubernetes deployment, which automatically targets all replicas of the AnythingLLM.
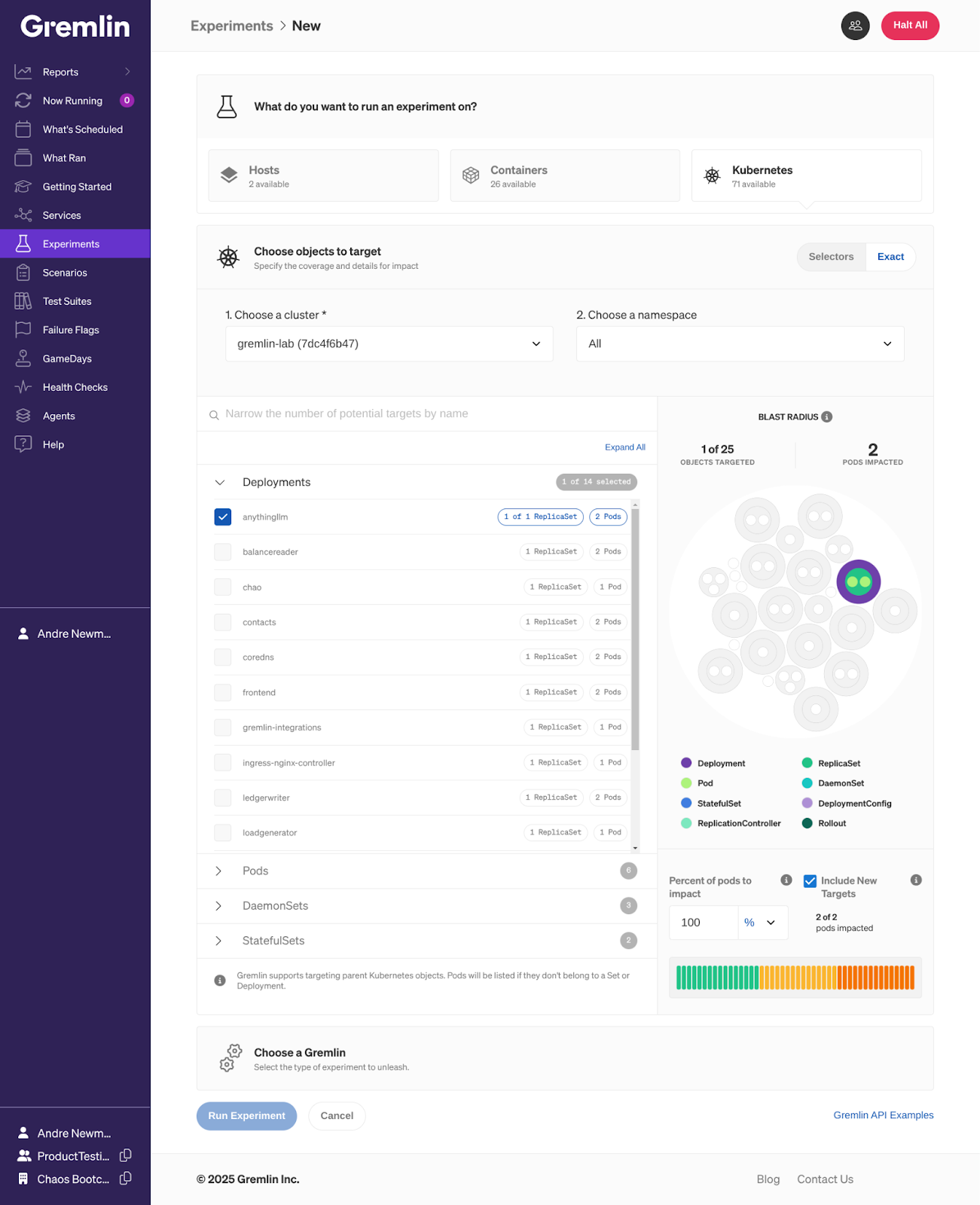
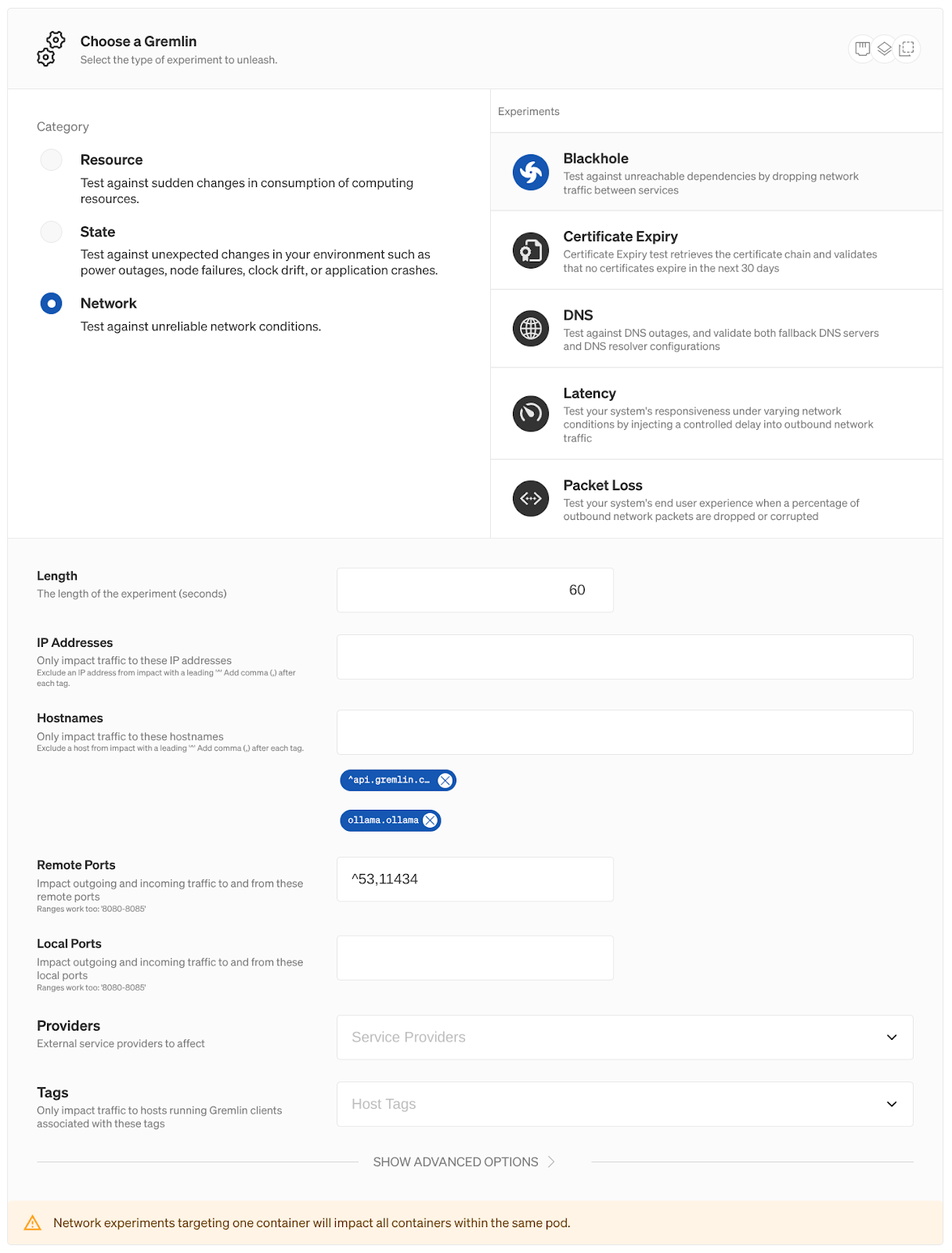
Why are we targeting AnythingLLM and not Ollama? We could drop all network traffic to Ollama, but for this experiment, we just want to test the connection between AnythingLLM and Ollama. To do this without impacting any other services that might be using Ollama, we’ll explicitly drop network traffic from AnythingLLM going to Ollama by adding Ollama’s hostname as an experiment parameter. This way, Gremlin only drops traffic from AnythingLLM to http://ollama.ollama. For even greater fine-tuning, we can specify the port Ollama is running on (11434 by default).
Unsurprisingly, AnythingLLM returns an error message when Ollama is unavailable. This is better than timing out or crashing, but it’s not an ideal user experience:
To avoid this in a real-world environment, we could scale up our Ollama deployment to at least two replicas running in at least two different availability zones (AZs). We could then repeat our test, only selecting one AZ instead of the entire deployment. If we’ve configured our cluster correctly, Kubernetes should automatically fall back to the second replica:
Standardizing and running regular outage experiments
We ran a one-off experiment, but what if we want to make this a regular part of our development process? We can use Gremlin’s Reliability Management features to run the test. Reliability Management standardizes experimentation by providing a pre-built suite of tests, which you can run on every service in your environment. It also tracks the results of each test ran on each service to create a reliability score, indicating the service’s overall reliability. This makes it useful not just for regularly running tests, but for finding reliability gaps in your services.
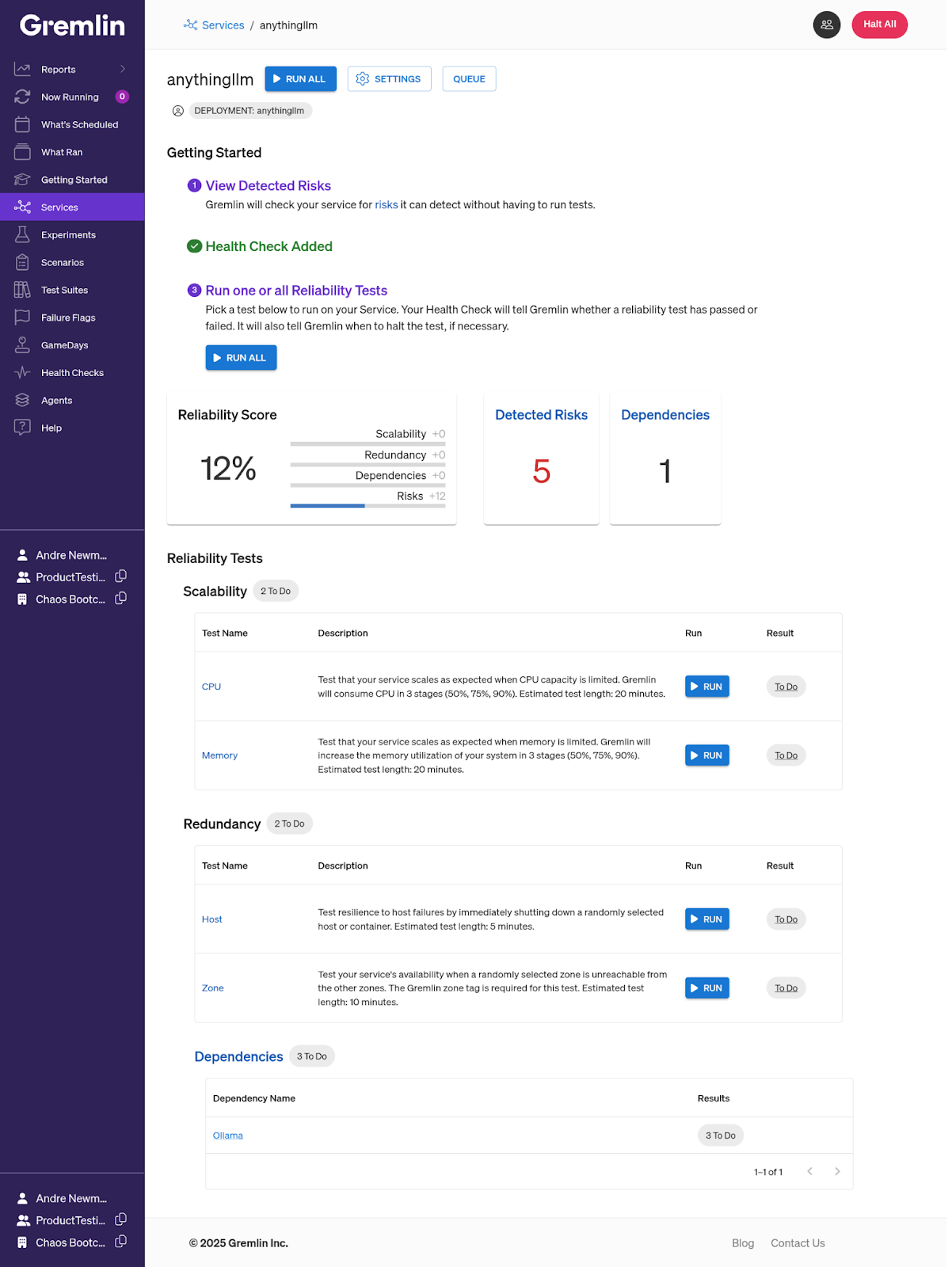
In our case, Gremlin automatically detected AnythingLLM and created a service. It also automatically detected Ollama as a dependency. To start testing, we need to set up a Health Check, an automated check that monitors your service using your observability tooling. In this case, Gremlin is simply querying AnythingLLM for the list of AI providers and models used in the workspace. In a production environment, you should use metrics that accurately represent your system’s stability, like query throughput.
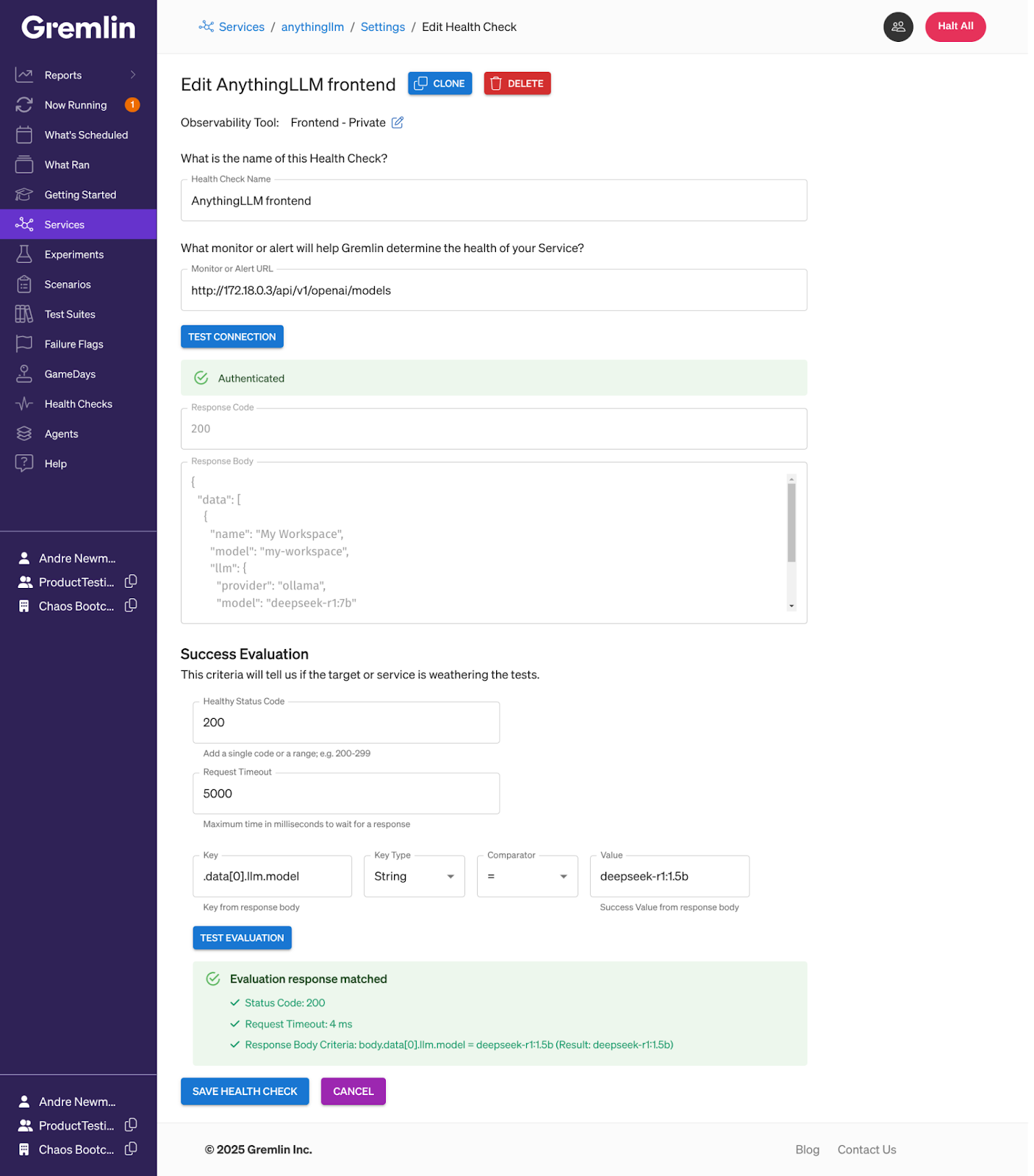
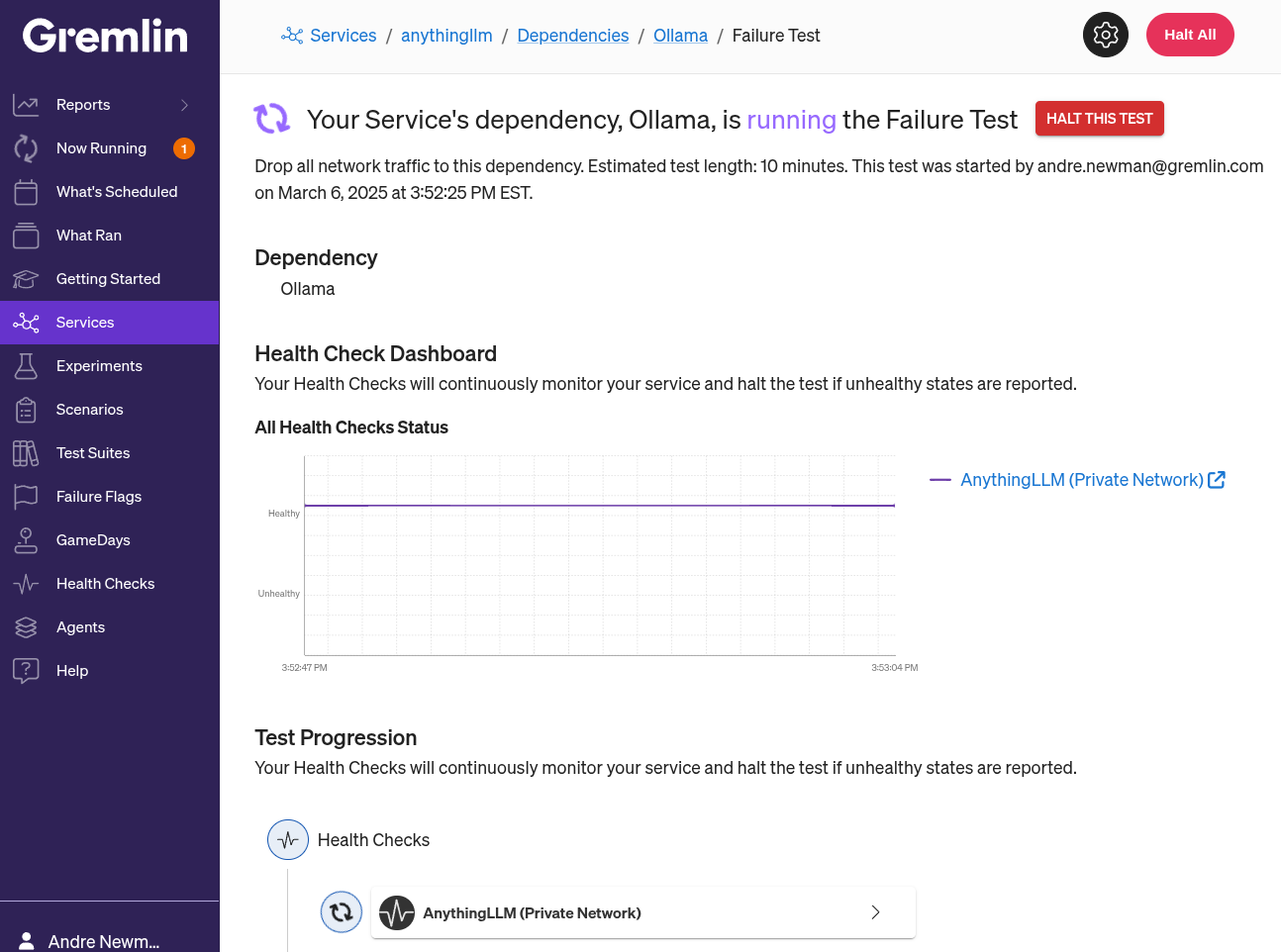
After we’ve added a Health Check, we can run a blackhole test directly on Ollama from AnythingLLM’s overview page. Gremlin will drop network traffic and use our Health Check to monitor AnythingLLM during the test.
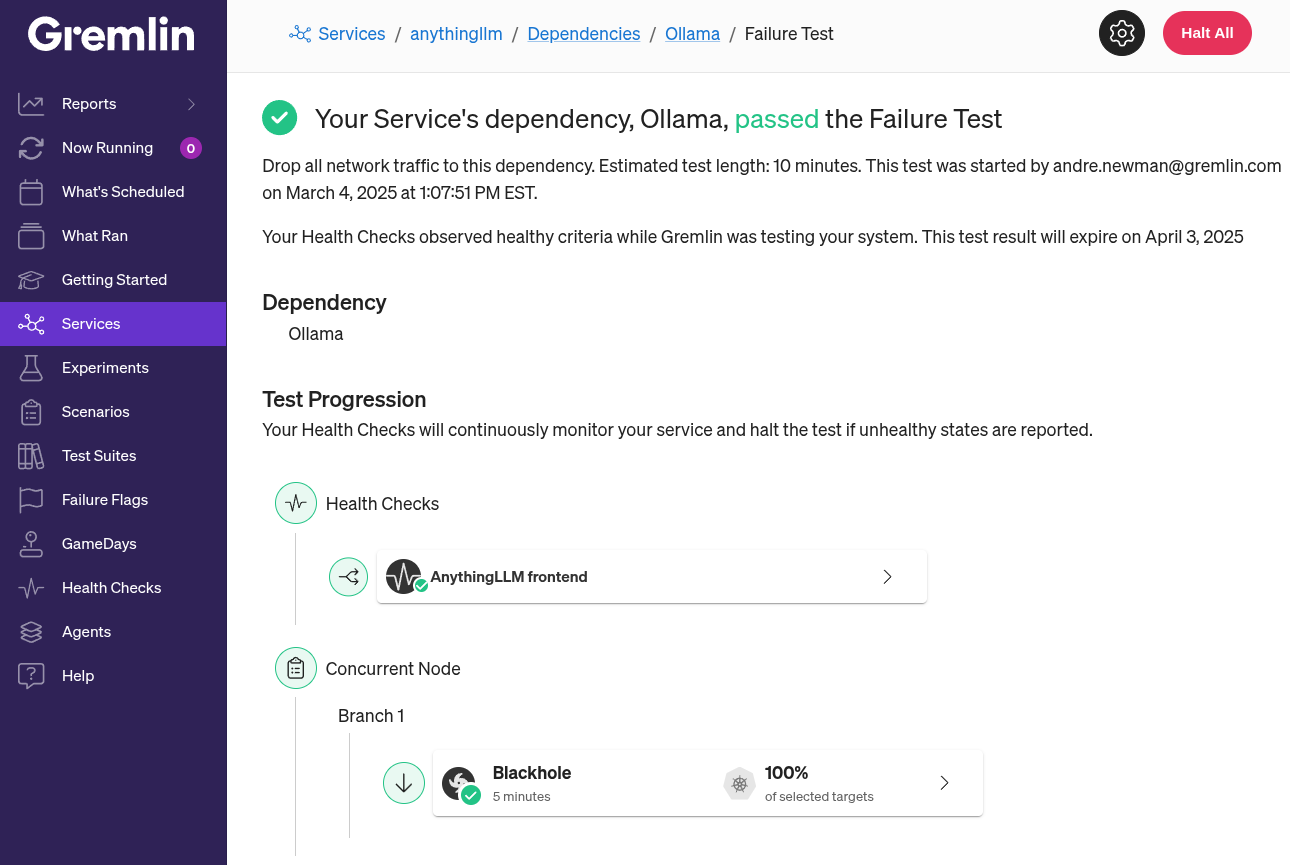
If the test completes without a single error from the Health Check, we pass. If the Health Check returns an error at any time, Gremlin immediately stops the test, returns AnythingLLM to its normal operation, and we fail the test. Fortunately for us, the test completed with no errors. Gremlin records a pass, and we get a nice boost to our reliability score.
Next steps
You may have noticed that many other tests are available to run. This is called a Test Suite, and while they’re customizable, Gremlin includes two designed to test for the most common failure modes. We recommend running each test on your services (Gremlin includes a handy “Run All Tests” button at the top of each service’s overview page) and then scheduling tests to run weekly. Like regular QA tests, regular reliability testing uncovers regressions and ensures changes to your code or environment don’t impact reliability.
Try to get your reliability score as high as possible!
Gremlin's automated reliability platform empowers you to find and fix availability risks before they impact your users. Start finding hidden risks in your systems with a free 30 day trial.
sTART YOUR TRIALSee Gremlin in action with our fully interactive, self-guided product tours.
Take the tourHow to make your AI-as-a-Service more resilient
Getting an AI-powered service up and running is hard; keeping it running is even harder. Read how AI-as-a-service systems can fail and how Gremlin makes them reliable.


Getting an AI-powered service up and running is hard; keeping it running is even harder. Read how AI-as-a-service systems can fail and how Gremlin makes them reliable.
Read moreReliable AI models, simulations, and more with Gremlin's GPU experiment
Build more resilient machine learning and AI models, video streaming, simulations, and more with Gremlin’s GPU experiment.

Build more resilient machine learning and AI models, video streaming, simulations, and more with Gremlin’s GPU experiment.
Read more10 Most Common Kubernetes Reliability Risks
These Kubernetes reliability risks are present in almost every Kubernetes deployment. While many of these are simple configuration errors, all of them can cause failures that take down systems. Make sure that your teams are building processes for detecting these risks so you can resolve them before they cause an outage.


These Kubernetes reliability risks are present in almost every Kubernetes deployment. While many of these are simple configuration errors, all of them can cause failures that take down systems. Make sure that your teams are building processes for detecting these risks so you can resolve them before they cause an outage.
Read more