
In today’s distributed, cloud-native world, network connectivity is just as important as reliable hardware. The migration from monoliths to microservices and on-prem datacenters to public clouds means our applications are much more dependent on healthy networks. But as systems become more distributed and network diagrams become more complex, so does the risk of failure. If a network card, switch, router, API gateway, firewall, or ethernet cable fails, it could take our entire application offline. We need to design applications and services to be resilient to these kinds of failures, and the Blackhole attack can help.
In this blog, we’ll take an in-depth look at the Blackhole attack and how you can use it to make your applications more resilient to network outages. We’ll explain how it works, how you can apply it, and how it can help your team and organization build more reliable systems.
How does a Blackhole attack work?
The Blackhole attack works by blocking network traffic from a host or container. It drops Internet Protocol (IP) packets at the transport layer by using traffic policing features built into the Linux Kernel and the Windows Filtering Platform for Windows hosts. By default, all inbound and outbound network traffic is dropped (except for DNS traffic and traffic to api.gremlin.com), but you can configure the attack to only impact specific types of traffic based on port, IP address, hostname, and other parameters. Gremlin also provides a list of pre-defined third-party services that you can select for easy targeting, such as an AWS EC2 region.
The attack supports these parameters:
- <span class="code-class-custom">Length</span>: How long the attack runs for.
- <span class="code-class-custom">IP Addresses</span>: Restricts the attack to specific IP address(es). This field supports CIDR values (e.g. <span class="code-class-custom">10.0.0.0/24</span>).
- <span class="code-class-custom">Device</span>: The network interface to impact traffic on. If left blank, Gremlin will target all network interfaces.
- <span class="code-class-custom">Hostnames</span>: Only impacts traffic to these hostnames.
- <span class="code-class-custom">Remote ports</span>: Only impacts traffic to these destination ports.
- <span class="code-class-custom">Local ports</span>: Only impacts traffic originating from these ports.
- <span class="code-class-custom">Protocol</span>: Which protocol to impact (TCP, UDP, or ICMP).
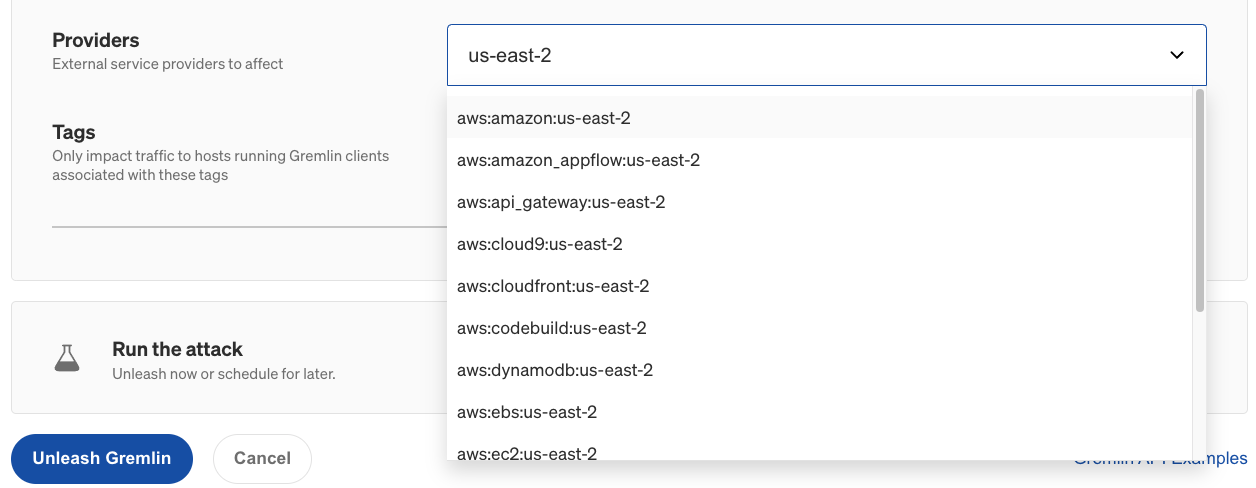
- <span class="code-class-custom">Providers</span>: Which external service provider(s) to impact, if any. To access this option in the Gremlin web app, click "Show Advanced Options".
- <span class="code-class-custom">Tags</span>: If specified, the attack will only run on Gremlin agents associated with these tags.
These parameters are called the magnitude of the attack. As you target a wider range of network traffic, the magnitude increases. As with all Gremlin attacks, you can run a Blackhole attack on multiple hosts simultaneously. This is called the blast radius. You can also run a Blackhole attack on containers, Kubernetes resources, and Services.
When running your first Blackhole attack, start small by reducing the magnitude and blast radius as much as possible. Target a single non-production host, and choose a single port number or service to impact. For example, if you're running a web server such as Apache or Nginx, only block port 80 (or 443 if using TLS). While the attack is running, monitor the availability of your service using a network monitoring tool, or even a basic connection testing tool like ping or traceroute.
As you run these experiments, remember to record your observations, discuss the outcomes with your team, and track any changes or improvements made to your systems as a result. This way, you can demonstrate the value of the experiments you’ve run to your team and to the rest of the organization.
Why should you run Blackhole attacks?
It's easy to take stable network connections for granted, especially in a public cloud where everything depends on fast, highly available networks. But network connections can fail for any number of reasons, including:
- Failures in downstream systems (dependencies).
- Misconfigured firewall and router rules, such as the 2021 Fastly outage.
- Saturation caused by unexpected surges in user traffic, high-bandwidth data transfers, or other causes.
- Hardware failures in network cards, routers, switches, gateways, and other network devices.
- Applications with poorly configured connection, timeout, and/or retry logic.
With Blackhole attacks, we can validate that:
- Our disaster recovery (DR) plans and business continuity plans (BCP) are up-to-date and effective.
- Our applications can withstand dependency failures.
- Clustered workloads, like Kubernetes or Kafka, can continue even if a master node fails.
- Our load balancers and API gateways are configured properly.
- Monitoring and alerting systems are configured correctly.
This helps us maintain high availability, reduce the risk of downtime, and provide a better overall experience for our customers.
Get started with Blackhole attacks
Now that you know how the Blackhole attack works, try running it yourself:
- Log into your Gremlin account (or sign up for a free trial).
- Create a new attack and select a host to target. Start with a single host to limit your blast radius.
- Under Choose a Gremlin, select the Network category, then select Blackhole.
- ^Set the Length of the attack.
- Optionally, enter the IP Addresses or Hostnames to drop traffic to, the network Device to impact, and the Remote or Local Ports to drop traffic on. For convenience, you can select an external service Provider to target, as well as target specific hosts by Tags.
- ^If you leave all of these options at their default values, all traffic will be dropped.
- ^Optionally, open the Show Advanced Options section and select the network Protocol to impact traffic on. By default, all protocols will be impacted.
- Click Unleash Gremlin to start the attack.
Make sure you have your network monitoring tool running during the attack, and compare your observations to your hypothesis:
- If you're testing a dependency failure, is your application or service still up? Does it respond the way you expected? Is there any added latency?
- If you terminated a node in a cluster, did the cluster keep running? Were any of the workloads running on the cluster terminated, or did they get rescheduled properly? Was there any noticeable downtime?
- Did your High Availability (HA) cluster remain available? Were you still able to connect to your cluster's control plane?
- Did your monitoring and alerting solution detect and report the outage? Was anyone on your team notified that the system had dropped off of the network?
- If you're testing a disaster recovery plan, did it work the way you expected to? Did any of the steps fail or result in an unexpected outcome?
Once you’ve answered your initial hypothesis, try increasing the magnitude of your attack by adding additional port numbers, IP addresses, or hostnames. Try blocking commonly used system ports like port 22 (SSH), 67 and 68 (DHCP), or 80 and 443 (HTTP and HTTPS).
You can also increase the blast radius by targeting more hosts simultaneously. This can be used to simulate large-scale network outages, such as an availability zone (AZ) or region outage. If your systems are deployed on AWS, what happens when one of your AZs can no longer be reached? To simulate an AZ outage, you can either select the hosts running in that AZ by tag, or select all hosts and use the Providers drop-down to select the AZ that you want to block traffic to.

Now that you’ve run the attack, try using a Scenario. Scenarios allow you to run multiple attacks sequentially, as well as monitor the availability of the target system(s) using Health Checks. Health Checks can periodically contact a monitor that you provide before, during, and after a Scenario, and if the monitor returns a failed state or fails to respond successfully or within a window of time, then the Scenario will automatically halt.
If you'd like guidance on where to start, try using one of our Recommended Scenarios. Gremlin includes over ten pre-built Scenarios designed by our reliability experts for testing conditions such as dependency outages, region evacuation, split brain conflicts, and database failovers. It's a quick and easy way to get started. Links to these Scenarios are available below.
When a dependency is unavailable, the user experience fails gracefully. Functionality will degrade, transparent to the user with a non-essential dependency, or a relevant error is displayed if the dependency was essential.
Length:
6 steps
Attack Type
Blackhole
.svg)
When a region becomes unavailable, traffic fails over to designated available regions, triggered automatically or manually. These regions handle the increased traffic, without any errors to the user.
Length:
2 steps
Attack Type
Blackhole

Gremlin's automated reliability platform empowers you to find and fix availability risks before they impact your users. Start finding hidden risks in your systems with a free 30 day trial.
sTART YOUR TRIALHow to troubleshoot unschedulable Pods in Kubernetes
Kubernetes is built to scale, and with managed Kubernetes services, you can deploy a Pod without having to worry...
.webp)
Kubernetes is built to scale, and with managed Kubernetes services, you can deploy a Pod without having to worry...
Read moreHow to fix Kubernetes init container errors
One of the most frustrating moments as a Kubernetes developer is when you go to launch your pod, but it fails to start…

One of the most frustrating moments as a Kubernetes developer is when you go to launch your pod, but it fails to start…
Read more